The adoption of generative AI in corporate mobile applications can no longer rely solely on external APIs. Latency, costs, and privacy are critical constraints that directly impact user experience and operational efficiency. For companies handling sensitive information, data sovereignty and local model execution have become clear competitive advantages.
In this article, we explore how RAG (Retrieval-Augmented Generation) and local LLMs (Large Language Models) allow the creation of high-performance mobile apps, maintaining privacy, reducing costs, and improving key KPIs.
The Problem with Cloud Dependency: Latency, Costs, and Privacy
Relying exclusively on cloud models (like GPT APIs) introduces several challenges:
- Latency: Each request requires a round trip to external servers, affecting real-time performance.
- Costs: Usage-based APIs can quickly become expensive as query volume increases.
- Privacy and Data Sovereignty: Sensitive data must leave the corporate infrastructure, creating regulatory and reputational risks.
The solution is a hybrid or fully local execution using RAG and on-device LLMs.
What is RAG and Why is it the Standard for Corporate Apps?
RAG combines retrieval + generation, allowing models to consult private knowledge bases without exposing sensitive data to the cloud.
Connecting AI with Private Corporate Data Without Sending it to the Model
- Corporate documents are converted into local embeddings.
- A user query is transformed into a vector and compared against the vector database.
- Only the most relevant information is sent to the LLM, which generates the final response on-device or in controlled environments.
Which are the Corporate Benefits? Privacy is guaranteed, compliance is ensured, and full data control is maintained, while ROI and KPIs related to productivity and process efficiency are optimized.
On-Device LLMs: Execution with Llama.cpp and MLC LLM
Thanks to quantization techniques, 7B parameter models can run on devices like the iPhone 15 Pro, consuming significantly less CPU and battery than cloud execution.
- Llama.cpp: Enables efficient LLM inference on iOS and Android.
- MLC LLM: Optimized for Metal/CPU/GPU on Apple Silicon, running complex tasks offline.
What does this mean?
Imagine an AI model as an enormous cookbook with 7 billion instructions (the “7B parameters”). Previously, to use it, you had to send it to a giant chef in the cloud (a remote server), who would follow the recipe and send back the result. This worked, but had downsides: slower responses, cost per request, and your ingredients (data) had to leave your control.
Now, thanks to quantization, we can compress that huge cookbook so it fits on your iPhone 15 Pro without losing the essential instructions. It’s like having a highly efficient, condensed version you can use directly in your kitchen.
- Llama.cpp: Helps you read and use the compressed cookbook quickly and efficiently on iPhone or Android.
- MLC LLM: Takes full advantage of the iPhone’s processor and GPU to run complex recipes offline, without draining battery or requiring internet.
In other words, you can run powerful AI directly on your device, fast, secure, and independent of external servers — like having a top chef in your pocket.
Local vs Cloud Consumption Comparison
Model | Latency | CPU Usage | Battery Usage | Privacy |
Cloud 7B | 200–400ms | Low on device | Low | Low (data travels to cloud) |
Local 7B | 50–100ms | Moderate | Moderate | High (data never leaves device) |
Vector Data Management on Mobile: SQLite + VSS and Alternatives
Managing local embeddings requires efficient vector storage:
- SQLite + optimized vectors (VSS): Lightweight, fast, and native.
- Alternatives: FAISS, Milvus, or Pinecone (for hybrid architectures).
- Supports fast, scalable queries on apps with thousands of sensitive documents.
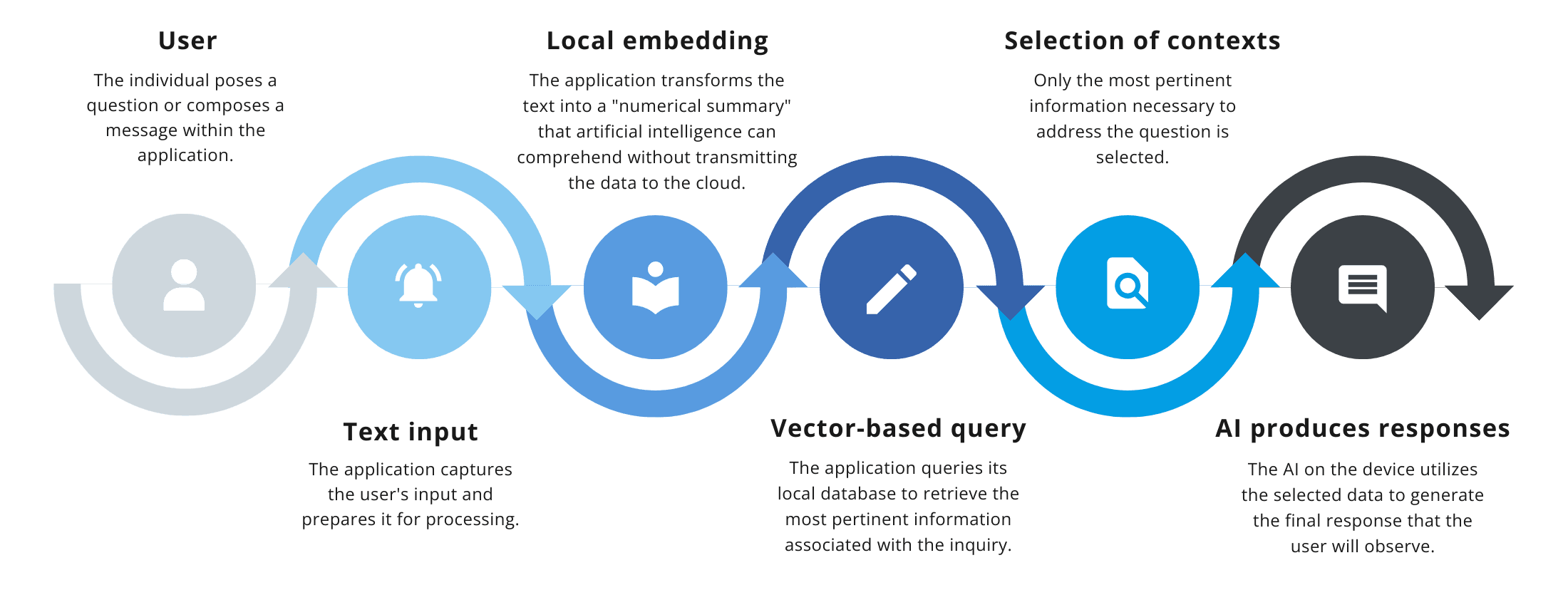
Conceptual Flow Diagram:
User → Text Input → Local Embedding → Vector Database Query → Relevant Context Selection → Local LLM Generates Response
- User: The person asks a question or types a message in the app.
- Text Input: The app receives the text and prepares it for processing.
- Local Embedding: Converts the text into a “numeric summary” the AI can understand without sending data to the cloud.
- Vector Database Query: Searches the local database for the most relevant information.
- Relevant Context Selection: Chooses only the information needed to answer the query.
- AI Generates Response: The on-device AI creates the final answer the user sees.
This ensures corporate information never leaves the device.
Real-World Use Cases: From Offline Assistants to Sensitive Document Analysis
- Offline corporate assistants: Internal support without exposing data to the cloud.
- Legal or financial document analysis: Extract critical information safely.
- Smart mobile apps: Instant responses for users, optimizing latency and experience.
The impact on KPIs and ROI is tangible: faster queries, reduced dependency on external infrastructure, and improved corporate security.
Data Sovereignty as a Competitive Advantage
In short, RAG and local LLMs represent the cutting edge of generative AI for mobile apps. By running models directly on the device and controlling embeddings locally:
- Sensitive data is protected.
- User experience is faster and smoother.
- Costs and ROI are optimized.
- Your company positions itself as a tech leader in a niche with low technical competition.
For companies demanding privacy, control, and efficiency, data sovereignty is no longer optional, it’s a strategic, competitive advantage.
If you’d like to learn how we can help you, feel free to contact us here 👉 Contact