La adopción de IA generativa en aplicaciones móviles corporativas ya no puede depender únicamente de APIs externas. Latencia, costes y privacidad son limitaciones críticas que impactan directamente en la experiencia del usuario y en la eficiencia operativa. Para empresas que manejan información sensible, la soberanía del dato y la ejecución local de modelos se han convertido en ventajas competitivas claras.
En este artículo exploramos cómo RAG (Retrieval-Augmented Generation) y LLMs locales (Large Language Model) permiten construir apps móviles de alto rendimiento, manteniendo privacidad, reduciendo costes y mejorando KPIs clave.
El problema de la dependencia de la nube: Latencia, costes y privacidad
El uso exclusivo de modelos en la nube (como GPT en APIs) introduce varios retos:
- Latencia: Cada consulta requiere ida y vuelta a servidores externos, afectando la experiencia en tiempo real.
- Costes: Las APIs basadas en consumo pueden escalar rápidamente según el volumen de consultas.
- Privacidad y soberanía de datos: Los datos confidenciales deben enviarse fuera de la infraestructura corporativa, creando riesgos regulatorios y reputacionales.
La solución sería una ejecución híbrida o completamente local con RAG y LLMs en el dispositivo.
¿Qué es RAG y por qué es el estándar para apps corporativas?
RAG combina retrieval (recuperación) + generación, permitiendo que los modelos consulten bases de conocimiento privadas sin exponer datos sensibles a la nube.
Conectando la IA con los datos privados de la empresa sin subirlos al modelo
- Los documentos corporativos se convierten en embeddings locales.
- Una consulta del usuario se transforma en vector y se compara contra la base de datos vectorial.
- Solo la información más relevante se pasa al LLM, que genera la respuesta final on-device o en entornos controlados.
¿El beneficio corporativo? Se garantiza la privacidad, el cumplimiento normativo y control completo de los datos, mientras se optimiza el ROI y los KPIs relacionados con productividad y eficiencia de procesos.
LLMs en el dispositivo (On-device): Ejecución con Llama.cpp y MLC LLM
Gracias a técnicas de quantization, modelos de 7B parámetros pueden ejecutarse en dispositivos como un iPhone 15 Pro, con un consumo de CPU y batería significativamente menor que la ejecución en la nube.
- Llama.cpp: Permite inferencia eficiente de LLMs en iOS y Android.
- MLC LLM: Optimizado para Metal/CPU/GPU en Apple Silicon, ejecutando tareas complejas offline.
¿Qué quiere decir esto? Imagina que un modelo de IA es como un enorme libro de recetas con 7.000 millones de instrucciones (eso son los “7B parámetros”). Antes, si querías usar ese libro, tenías que enviarlo a un chef gigante en la nube (un servidor remoto) que hacía la receta por ti y luego te enviaba el resultado. Esto funcionaba, pero tenía problemas: tardaba un poco, se gastaba dinero por cada receta que pedías y además tenías que enviar tus ingredientes (datos) al chef, lo que no siempre es seguro.
Ahora, gracias a algo llamado quantization, podemos comprimir ese libro gigante para que quepa en tu iPhone 15 Pro sin perder las instrucciones importantes. Es como si tuvieras una versión resumida y súper eficiente del libro, que puedes consultar directamente desde tu cocina.
- cpp: es como una herramienta que te ayuda a leer y usar ese libro comprimido rápido y eficientemente en tu iPhone o en un Android.
- MLC LLM: es otra herramienta que está especialmente diseñada para sacar el máximo provecho del procesador y la tarjeta gráfica de tu iPhone, permitiéndote hacer recetas complejas sin necesidad de conectarte a internet y sin que se agote tu batería rápidamente.
Es decir, puedes usar una IA muy potente directamente en tu teléfono, rápida, segura y sin depender de un servidor externo, como tener un chef experto justo en tu bolsillo.
Comparativa de consumo local vs en la nube:
Modelo | Latencia | Consumo CPU | Consumo Batería | Privacidad |
Nube 7B | 200–400ms | Bajo en dispositivo | Bajo | Baja (datos viajan a la nube) |
Local 7B | 50–100ms | Moderado | Moderado | Alta (datos nunca salen) |
Gestión de datos vectoriales en el móvil: SQLite + VSS y alternativas
La gestión de embeddings locales requiere almacenamiento vectorial eficiente:
- SQLite + vectores optimizados (VSS): Ligero, rápido y nativo.
- Alternativas: FAISS, Milvus o Pinecone (para arquitecturas híbridas).
- Permite consultas rápidas y escalables en apps con miles de documentos sensibles.
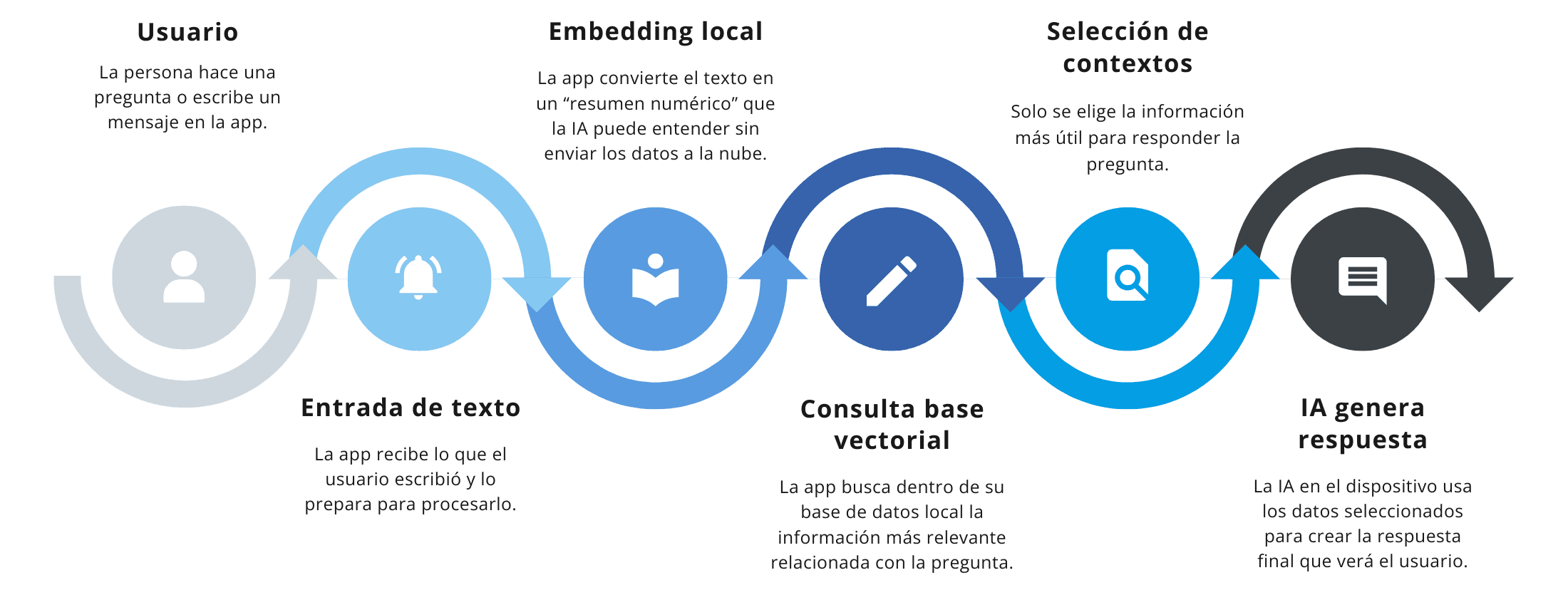
Diagrama de flujo conceptual:
Usuario -> Entrada texto -> Embedding local -> Consulta base vectorial -> Selección contextos relevantes -> LLM local genera respuesta
- Título: Usuario
Texto: La persona hace una pregunta o escribe un mensaje en la app. - Título: Entrada de texto
Texto: La app recibe lo que el usuario escribió y lo prepara para procesarlo. - Título: Embedding local
Texto: La app convierte el texto en un “resumen numérico” que la IA puede entender sin enviar los datos a la nube. - Título: Consulta base vectorial
Texto: La app busca dentro de su base de datos local la información más relevante relacionada con la pregunta. - Título: Selección de contextos
Texto: Solo se elige la información más útil para responder la pregunta. - Título: IA genera respuesta
Texto: La IA en el dispositivo usa los datos seleccionados para crear la respuesta final que verá el usuario.
Esto asegura que la información corporativa nunca abandone el dispositivo.
Casos de uso reales: Desde asistentes offline hasta análisis de documentos sensibles
- Asistentes corporativos offline: Soporte interno sin exponer datos a la nube.
- Análisis de documentos legales o financieros: Extracción de información crítica sin riesgo de fuga.
- Apps móviles inteligentes: Respuestas instantáneas para usuarios, optimizando latencia y experiencia.
El impacto en KPIs y ROI es tangible: reducción de tiempos de consulta, menor dependencia de infraestructura externa y mejora de la seguridad corporativa.
La soberanía del dato como ventaja competitiva
En resumen, RAG y LLMs locales representan la vanguardia de la IA generativa aplicada a apps móviles. Al ejecutar modelos directamente en el dispositivo y controlar los embeddings localmente:
- Proteges datos sensibles.
- Aumentas velocidad y experiencia de usuario.
- Optimiza costes y ROI.
- Posiciona tu empresa como líder tecnológico en un nicho con poca competencia técnica.
Para empresas que exigen privacidad, control y eficiencia, la soberanía del dato se convierte en una ventaja estratégica y competitiva.
¿Buscas mejorar los procesos internos en tu empresa?